





人工智能 因果学习篇(2)-Causal Attention for Vision-Language Tasks(文献阅读)
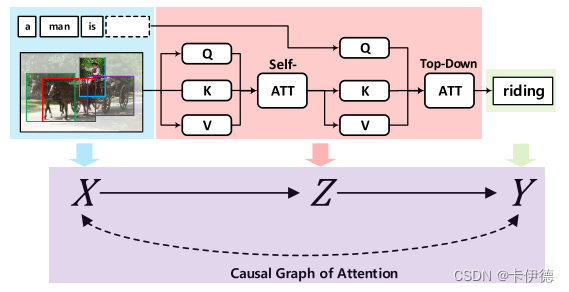
Causal Attention for Vision-Language Tasks 引言   这篇论文是南洋理工大学和澳大利亚莫纳什大学联合发表自2021年的CVPR顶会上的一篇文献,在当前流行的注意力机制中增加了因果推理算法,提出了一种新的注意力机制:因果注意力(CATT),使用因果推断中的“前
2024-03-06 19:57:54 2948 2 5
阅读详情



最新评论
张
张苹果博客
评:友情链接你好博主,麻烦把“VAE+”这个友链删除,已经不用了。更换最新友链地址: 名称:张苹果 网址:https://zhangpingguo.com 图标:https://zhangpingguo.com/logo.jpg 描述:这个人很简单,没什么好说的。
b
bobo live casino
评:留言我觉得你提到的这个问题很有意思,也很实用。根据我的经验,可能有几个方向可以尝试: 确认一下基础设置:有时候问题可能出在一些小的配置或设置上,可以重新检查一下相关的设置,看看有没有什么遗漏。 参考一些常见问题解答(FAQ)或指南:有时候论坛里其他人可能遇到过类似的问题,查看一下FAQ或者其他人的建议可能能帮助你找到解决方法。 试试其他方法:如果当前的方法行不通,可以考虑其他的替代方案,或者逐步排除不同的可能性来找出问题的根源。
j
jiyouzhan
评:因果学习篇(2)-Causal Attention for Vision-Language Tasks(文献阅读)这篇文章写得深入浅出,让我这个小白也看懂了!
c
ccbbp
评:wordpress自动生成站点地图sitemap.xml教程博客很难了,新的百度不收了
楠
楠怪
评:wordpress自动生成站点地图sitemap.xml教程还搞博客呢
c
clash节点
评:友情链接友链申请 网站名称:clash节点 网站链接:https://clashgithub.com/ 网站头像:https://clashgithub.com/wp-content/themes/modown/static/img/logo.png 网站描述:免费公益SSR/V2ray/Shadowrocket/Clash节点/小火箭订阅链接|科学上网|免费梯子
机
机灵鬼
评:视频行为识别(一)——综述机
机灵鬼
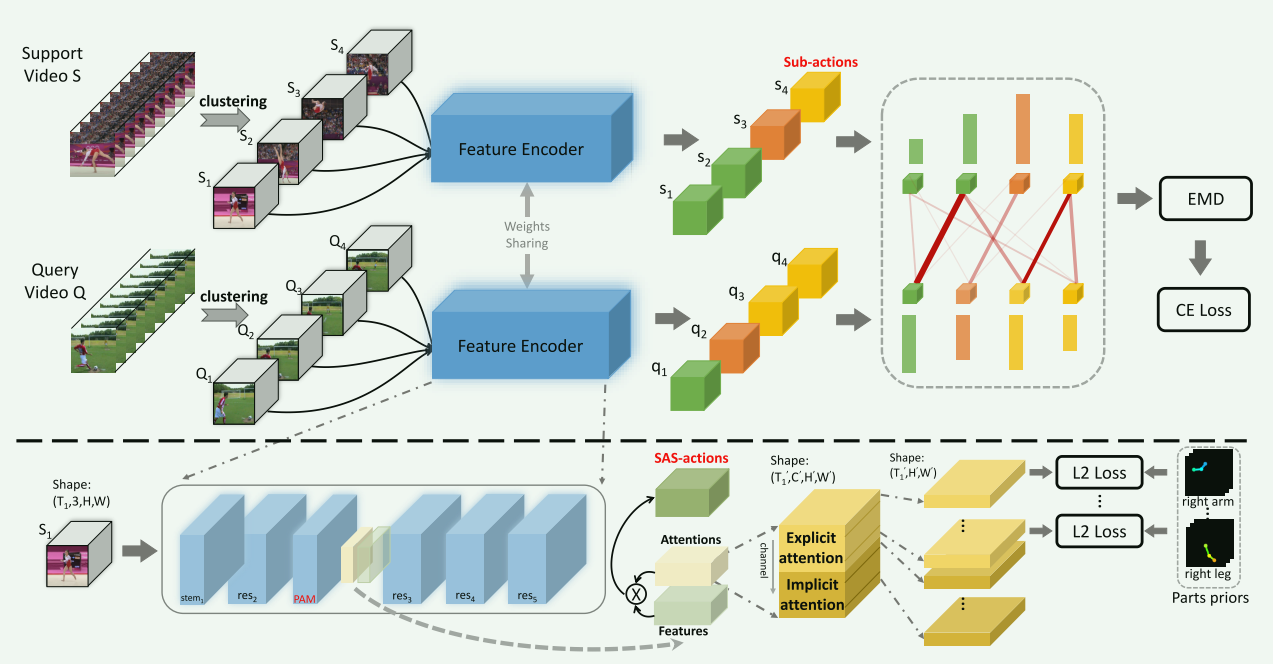
评:视频行为识别(二)——小样本动作识别的分层组合表示开
开心鬼
评:因果学习篇(1)-后门准则写的不错。

B
BG7ZAG
评:留言你的回复邮件发了两条,估计的插件冲突了,一条是主题自带的评论回复,一条比较简单的文本回复 [图片]