因果学习篇(2)-Causal Attention for Vision-Language Tasks(文献阅读)
分类: 人工智能 2934 2
Causal Attention for Vision-Language Tasks
引言
这篇论文是南洋理工大学和澳大利亚莫纳什大学联合发表自2021年的CVPR顶会上的一篇文献,在当前流行的注意力机制中增加了因果推理算法,提出了一种新的注意力机制:因果注意力(CATT),使用因果推断中的“前门准则”解决训练数据中存在的虚假相关性,刨析了注意力机制在推理过程中的因果原理,在提高模型性能的前提下,加强了模型的可解释性,打开了神经网络的黑匣子,具有非常好的参考意义。
此外,本文所提的因果注意力遵守了传统K-Q-V的机制,所以可以替换现有的各种自注意力机制,如Transformer,是一个可插拔的模块。
> 代码已开源:https://github.com/yangxuntu/lxmertcatt
> 原文链接:Causal Attention for Vision-Language Tasks
瓶颈问题
在传统的自注意力机制中,通常都是利用查询集Query和键集Key相乘得到权重,然后再更新值集Value。在该过程中,注意力的权重是无监督的,即注意力权重在训练过程中没有标注权重标签,这难免导致数据偏差。
举个例子:
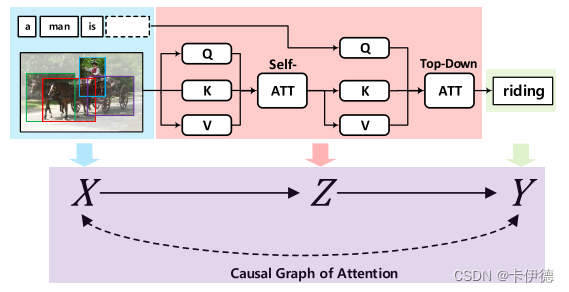
如上图展示了一个图像描述的流程,在训练数据中,因为有好多图片被描述为“人骑着马”,自注意力机制自然而然的会将“骑”这个动作与“人”、“马”关联起来。那么,在测试阶段,如果给一个“人驾驶马车”的图片,注意力机制会仍然用“人”和“马”进行关联,推断出“骑”这个动作,而忽略了“马车”。然而,该问题不会因为数据规模的扩大而解决,因为现实中确实红色苹果比绿色苹果多,站着的人比跳舞的人多。
该问题的本质原因就是混杂因子(因果推理中的专有名词)导致的,比如X和Y之间没有直接的因果关系,但是X和Y之间仍然相关。下面的因果结构图可以解释该理论:
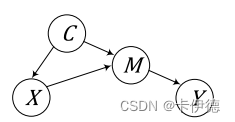
图中,X为输入图片,Y为标签,C表示常识(如人可以骑马),C是混杂因子,M是图片X中的目标。
C->X
- 表示视觉场景可以通过常识来生成;
- X->M表示场景中包含着多个目标;
- C->M表示目标可以由常识来决定;
- M->Y表示语言生成;
从因果图中可以看出,X->Y有两条路径:X->M->Y 和 X<-C->M->Y(含混杂因子)
因此,无论数据集多大,如果不知道混杂因子,仅使用P(Y|X)来训练模型,永远无法识别真正因果效应。
比如训练集中“人骑马”比“人驾驶马车”的数据多,测试集中后者比前者多,那么训练中的P(Y|X)将无法引用在测试中。
解决方法
- 提出了一个新的注意力机制:因果注意力(Causal Attention , CATT), 识别X->Y的因果效应,避免混杂因子造成的数据偏差。该方法使用了前门准则(无需混杂因子的假设知识);
- 提出了样本内注意力(ISATT)和跨样本注意力(CS-ATT),遵守Q-K-V操作;而且Q-K-V操作的参数也可以在IS-ATT和CS-ATT之间共享,以进一步提高某些架构中的效率。
- 在LSTM、Transformer和大规模视觉-语言预训练模型中进行了测试,验证了所提模块能够大幅改善模型性能。
方法
前门因果图中的注意力
如上面图中所示,在预测标签Y时,通常采用观测相关性P(Y|X),计算如下:

但是,该概率预测时可能学习到由后门路径Z<-X<->Y导致的错误相关性,而不是Z->Y的真正因果效应。
因此,需要使用因果干预切断X->Z这条后门路径,从而阻断Z<-X<->Y路径。方法是将输入X分成不同的情况{x},然后通过以下期望来测量Z对Y的平均因果效应:

其原理可以通过例子来解释:
比如图像描述数据集中有大量的“人和滑雪板”的数据,那么模型会学习到错误的“人”与“滑雪板”的关联关系,而不会人的性别;
CS-Sampling则将人和其他样本中的对象结合,比如自行车、镜子。
最终,预测概率如下:

以上过程称为前门准则。
IS-Sampling和CS-Sampling
IS-Sampling
对于上述的概率公式,可以将P(Y|Z,X)用一个softmax层的网络g()来表示,因为许多视觉-语言模型都是做分类的,其公式如下:
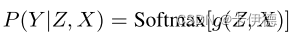
因此,需要采样X和Z,并送到网络中完成P(Y|do(X)),do表示对X进行干预(因果学习的内容)。
为降低复杂度,使用归一化加权几何平均数(NormalizedWeighted Geometric Mean,NWGM)近似地将外采样吸收为特征级别,实现只需要一次前向传播(我没懂,有懂得记得评论告诉我一哈)。具体公式如下:
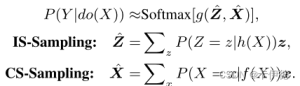
其中h和f都是特征编码函数,这里,我的理解可能就是将概率公式中的x,同样使用神经网络层来进行特征嵌入表示。x和z加粗表示向量。
IS-Sampling在实际计算中是按一个传统的注意力网络计算的,简单的表示为Q-K-V操作,结构下图蓝色部分。
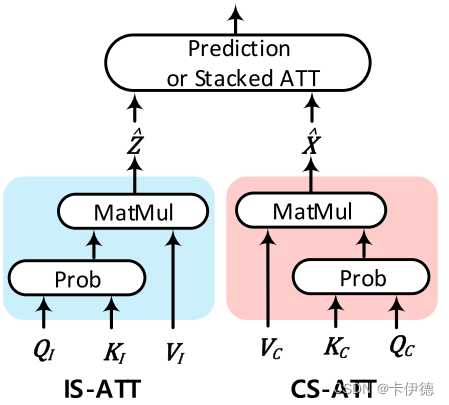
对应的,In-Sampling attention(IS-ATT)算法如下:
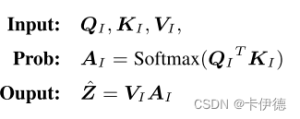
下标I表示IS-ATT。其中,所有的$K_I$和$V_I$都来源于当前输入样本特征,$Q_I$来源于h(X)。交叉模态i注意力中,查询向量表示的是句子上下文,而自注意力机制中查询向量表示的仍然是输入样本特征。对于$A_I$而言,每个注意力向量$a_I$都是IS-Sampling的P(Z=z|h(X))概率估计,输出$\hat{Z}$是IS-Sampling评估向量。
与IS-ATT类似,交叉样本注意力(Cross-Sample attention,CS-ATT)结构如上图红色部分,算法如下:
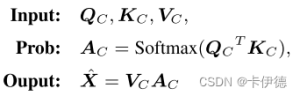
其中,$K_C$和$V_C$都来源于训练集中的其他样本,$Q_C$来源于$f(X)$。$a_C$近似$P(X=x|f(X))$,且$\hat{X}$是CS-Sampling评估向量。
最后,单一的因果注意力分别由IS-ATT和CS-ATT得到,然后,拼接这两个值作为最终$P(Y|do(X))$的值。
因果注意力(CATT)在堆叠注意力网络中的应用
- Transformer+CATT
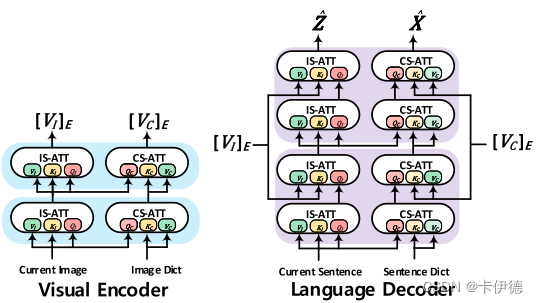
从图中可以看出,视觉-语言Transformer模型包含视觉编码器和文本解码器。在实现中,共包含六个蓝色和紫色的模块,编码器的输入包括当前图片和一个全局的图像嵌入字典(数据集所有文本的嵌入向量),编码器中IS-ATT和CS-ATT的输出输入到解码器中,用于学习视觉语言的表示。在解码器中,首先输入IS-ATT和CS-ATT的是当前的句子嵌入和全局嵌入字典,输出包括IS-Sampling和CS-Sampling两部分内容,将其进行拼接将作为最终的预测。
实验分析
本文在不同技术实现的视觉问答、图像描述两个任务上进行了实验。数据集有MS COCO、VQA2.0和Pre-training and Fine-tuning Datasets for VLP,实验结果如下。
图像描述
- 相似度度量
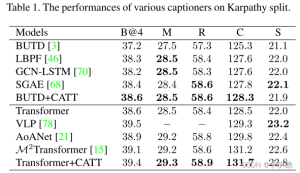
- 偏差度量
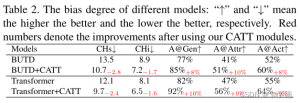
视觉问答
- 基于LSTM和Transformer的VQA模型性能对比
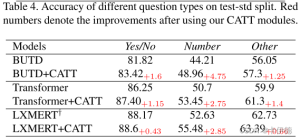
- 不同题型对测试标准分割的准确性
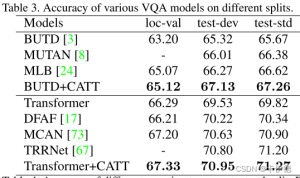
结论和展望
在本文中,利用因果推理来分析注意机制易被数据集偏差误导的原因,发现了注意机制是一个不正确的近似前门准则,无法捕捉输入和输出之间真正的因果关系。在此基础上提出了一种新的注意力机制-因果注意力(CATT),该机制通过消除混杂因子来提高注意机制的质量。具体来说,CATT包含样本内和样本间注意力,用于估计前门平差中的样本内和样本间注意力,两个注意力网络都遵循Q-K-V操作。
将CATT应用到各种流行的基于注意力的视觉语言模型,实验结果表明,它可以改善这些模型的相当大的性能。
共 2 条评论关于 “因果学习篇(2)-Causal Attention for Vision-Language Tasks(文献阅读)”